Pagination: The deceptively simple task

Software engineer based in Singapore
Welcome to my website, where I write mostly on tech-related content to share the things I learned from people and from building projects using different tools.
My interests are in tech, traditional finance, cryptocurrency.
Pagination is the process of separating data into multiple discrete pages. In the context of web and mobile applications, this can either be in the form on numbered pages as seen in google search results or infinite scrolling in social media feed. The decision process behind choosing either approach is not the objective of this post, but rather it is about the implementation of the backend data flow.
This is the first moderately technical post on this website, and I am happy to finally start writing a topic that is more related to the art of software engineering.
Why is pagination needed?
If a certain product feature does not yield benefit to end users, then it is worthless.
Pagination has been proven to improve user experience in a few ways:
Loading a small chunk of data each time reduces the data bandwidth usage, which ultimately improves page loading speed and Search Engine Optimisation(SEO). The benefit of downloading lesser data is more pronounced in places with poor network connectivity.
Splitting content into multiple pages helps to retain readers' attention, increasing the likelihood that they will enjoy their reads. Imagine how poor of a reading experience it will be if the home page of this website displays over 100 posts with its full content.

Overview
A few months into my job, I was learning and using cool technologies such as Elasticsearch, Redis. Elasticsearch is used for implementing a basic search feature, and Redis is used for optimising another aspect of search that is not related to the former.
Elasticsearch is a common tool used for products that want a comprehensive search experience for their end-users. It is a powerful full-text search engine that comes with great out-of-box features such as autocomplete, phrase suggestion, flexible analyser, tokeniser, query language.
I used Elasticsearch to implement the backend for the infinite scrolling experience on the mobile and web app. My preparation for this task included reading up what pagination is all about, several common implementations.
What I thought was a simple coding task turned out to be not so simple after all, when my team and I discovered inconsistencies and irregularities in the search result after a few months.
In short, the tragedy was due to an oversight in the overall data flow - the implementations that I have read up on have all their data processing requirements in a single place, whereas for my case the main data is in one place, and the secondary data is in another.
There are also other potential pagination issues to take note:
Data freshness. When data in the data store changed, should they be reflected in the current search session?
Bi-directional search. This is used in advanced cases of infinite scrolling where data a few pages outside of the current viewport are discarded to conserve memory, which also ties in with the data freshness issues
Indeed, pagination is one domain of software engineering which has been greatly researched, experimented, and implemented, yet there are still bad ones lying around.
Pagination v1.0: 3 simple steps
Here are the general steps taken to produce search results for any user query:
Query elasticsearch
Search for availability from another backend service
Return data that contain availability to user
The initial implementation is really straightforward. All I need to do is to use the from parameter from Elasticsearch as the offset - the number of documents to skip over. Next, call an availability API, and finally filter the search results that contain availability and return the end result.
The problem
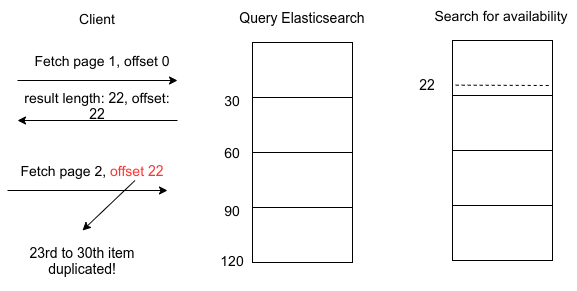
The major mistake in this implementation is that the offset passed to Elasticsearch does not account for the availability.
Wrong offset used for pagination
For example, a client sends a request for 30 items, Elasticsearch is queried and returns 30 results, but there is no guarantee that all 30 of them have availability, so let's say that after filtering availability we have 22 results. On the next request, the client sends requests for another 30 items and sends in offset 22 to skip the 22 items that are in the result set. This is a problem because Elasticsearch will return the 23rd item onwards, from which the 23rd to 30th item have already been searched and returned in the first request, resulting in duplication.
This fundamental logic error took some time to figure out, which led to a quickfix.
Pagination v1.1: The quick fix
After identifying the cause of the duplication problem, a fast rescue in en route. Instead of using the length of the result set returned(i.e. 22) as the offset, the length of the items searched so far is used as the offset(i.e. 30).
Problem solved! Well, not quite...
Another problem
The next problem encountered was that the search will tend to be terminated prematurely if the items with availability are further down the result set, which meant that those items will never appear on the search result page.

This is both damaging and non-damaging. From the perspective of the end-users, they may not suspect anything amiss because there are no strange happenings in the mobile and web application. From the perspective of the business, many items became undiscoverable, causing potential financial losses.
After 2 tries, it became clear that a two-step page-by-page fetch won't work no matter what. After doing more research, a more robust plan was born.
Pagination v2.0: Correctness first
Overview
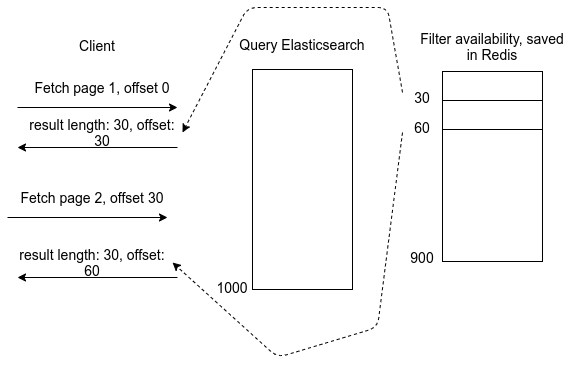
The main idea is to do a bulk fetch of data on the first request, filter for availability, and save the result ids in a Redis set, which are used for serving results to users for every page request. A UUID is used as the key to the result set, which functions as the search session key.
Essentially, for each query, a snapshot of the result set is computed and used to serve for subsequent pages.
For this implementation, the Redis sorted set data structure was chosen because it provides flexible and powerful ways to manipulate the data with zrange, zrangebylex.
The response payload looks something like this:
{
"payload": {
"total": 250,
"hasNext": true,
"sessionToken": "1d65df36-0072-4fe6-b396-9c851097a9e0",
"data": []
}
}
First page request
- Bulk fetch
The page size is set to 1000, which is not a high number. But given the data set we had at the time of implementation, it was more than enough.
- Check availability flags
This is a pre-processing step handled by a background job that periodically checks and saves a boolean flag for all merchants and timeslots combination in Redis.
- Save resulting id list
Save the resulting list of id with availability in Redis, with a default expiry of 30 minutes. The reason for saving id rather than the full data object is to reduce memory usage and data inconsistency.
- Get the full object data
With the list of ids, retrieve the full object data from Elasticsearch.
- Search for availability
Search for availability for the first 30 items and return the final result.
Subsequent page fetch
- Retrieve the list of ids
Use the search session key to retrieve the list of id using from Redis
- Get full object data
With the list of id, get the full object data from Elasticsearch.
- Search for availability
Search for availability for the first 30 items and return the final result.
Potential problems
1.Availability datafreshness from background job
The background job will take more time to complete as more data fills up Elasticsearch, resulting in a larger window of time that is out of sync with the actual availability. One possible solution is to spin up multiple worker threads to share the workload - 600 loop iterations are run for one single record.
2. Updates to Elasticsearch are not visible
Since the approach takes a snapshot of the result set that matched the query during the first request, updates to the data store will not be visible to the current search session.
For this case, this is a compromise that my team is willing to take to avoid another complicated task of combining and deduplicating the search results from old and new snapshot data.
3. What happens after the bulk fetched data is consumed?
In the example, 1000 items are fetched from Elasticsearch, filtered for availability and saved in Redis. If an incredible user manages to scroll through all 1000 items in the result page, and there are more data in Elasticsearch, another round of bulk fetch and availability filtering needs to take place.
But this works against point 2 above - the new bulk fetch is a newer snapshot of Elasticsearch, which is different from the snapshot of the initial bulk fetch.
One possible solution would be to have yet another background job to do subsequent bulk fetches(1001st to 2000th item, 2001 to 3000th item and so forth). The bulk fetch for the first page should be kept to a reasonable size in order for the request to complete fast enough.
Another way of handling this is to take the easy way to ignore any data after the initial bulk fetch data is consumed because it is highly unlikely that users will scroll through thousands of items to decide on a transaction. This may or may not be wise from a business point of view, and requires sufficient empirical evidence to back it up.
4. Memory hog by some users
Rogue or extremely enthusiastic users can trigger many search sessions in a short period of time, potentially causing Redis to run out of memory. This can cause a really poor user experience by evicting old data when they are still actively used.
There are a few measures to keep the probability of this happening low.
First, store only the necessary data in Redis, don't do a wholesale data dump. Next, a rate-limiting mechanism can be used to put a limit on the reasonable number of requests that can be made in a certain amount of time. Also, evict old data out of the data store, configuring the eviction policy to suit your own needs.
Other considerations
Q: Why not store availability in Elasticsearch, then most of the complexity will be gone.
A: I asked this question at the beginning of the solution design phase. The quick win is that search and availability filter will happen at the same place, so there is no need to introduce a cache layer, saving time and money immediately.
However, there are several drawbacks to storing availability, a fast-changing data, in Elasticsearch:
Every batch of availability data means a bulk update operation to Elasticsearch, which can affect query latency. If the frequency and volume of the availability data are huge enough, this will cause problems with user experience.
Storing an array of availability data as nested documents in Elasticsearch results in poor query performance. This is explained in an article by Go Jek where they encountered performance issues with nested documents. They solved the performance issue, but another custom solution that needs to be maintained and has its own inaccuracies.
Conclusion
Pagination in itself is a simple technical concept to understand. However, the devil is in the detail. A proper understanding of the acceptable user experience and tradeoffs is needed in order to design the technical approach. After all, making tradeoffs is at the heart of software engineering.